Normalmente asumimos que nuestros datos siguen una distribución Normal, pero en realidad, no es siempre así. Obtenemos un resultado, por ejemplo, en el cálculo del Cpk, y no sospechamos que tal vez, no estén reflejando la realidad. Cuanto más se aparten nuestros datos de la Normalidad, cuando esta sea un requisito del modelo estadístico, aumentará el error de los mismos, y nos alejaremos de las buenas decisiones.
Analicemos este grupo de datos
96, 95, 97, 95, 95, 97, 102, 100, 101, 103, 105, 106, 103, 102, 100, 103, 102, 103, 104 y 105
Nota: Respetar el orden de los datos
¿Cómo verificamos si estos datos siguen una distribución normal?
a. Realizando, por ejemplo, la Prueba de normalidad de Kolmogorov – Smirnov (KS).
i. H0: La distribución es Normal (Hipótesis nula)
H1: La distribución no es Normal (Hipótesis alternativa)
ii. Si trabajamos con un intervalo de confianza de 95 %, nuestro α será 0,05.
iii. Tomaremos el p-valor como prueba estadística
iv. La regla de decisión
Si el valor p, de esta prueba, es menor que el nivel de significancia elegido (α =0,05), se rechaza H0 (se acepta H1), y se concluye que se trata de una población No Normal. Si no podemos rechazar la H0, asumiremos que la distribución es Normal
v. Tomar la decisión de aceptar o rechazar H0.
¿Cómo lo hacemos en Minitab?
a. Cargamos una columna con los datos a verificar en la planilla Minitab
b. Seleccionamos la ruta descripta en la figura siguiente
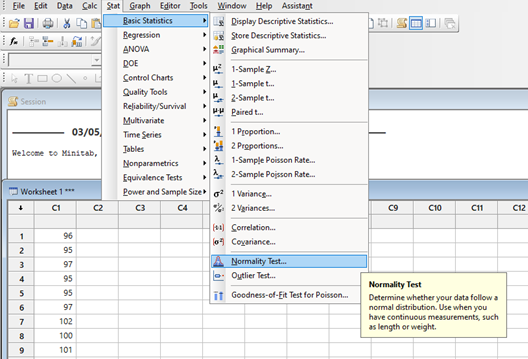
c. Aceptando en Test de Normalidad, se abre el siguiente cuadro de diálogo.
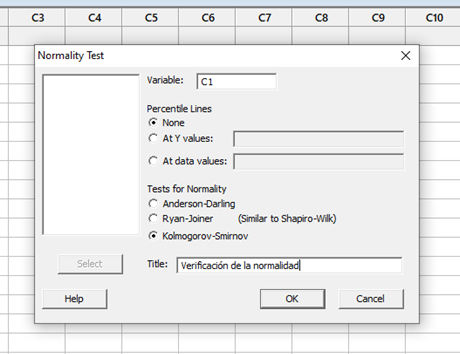
Completamos la variable seleccionada, en nuestro caso es la columna 1 (C1)
Elegimos el test seleccionado (KS),
Colocamos el título
Hacemos click el OK
Aparece el siguiente gráfico
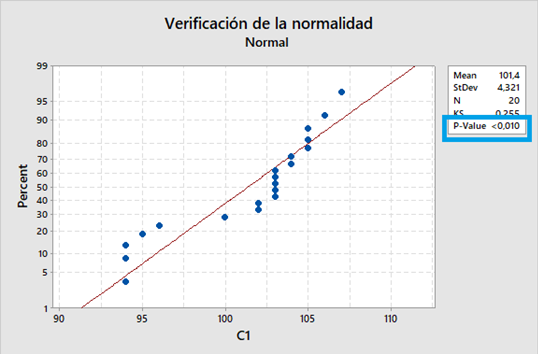
El Valor p es menor que α (0,05), por lo tanto, rechazamos la H0, No es una distribución Normal.
Si la distribución debe ser Normal, como requisito para el modelo estadístico que vamos a utilizar, debemos intentar normalizar los datos.
Utilizaremos la transformación de Box Cox
Seleccionamos la ruta descripta en la figura siguiente
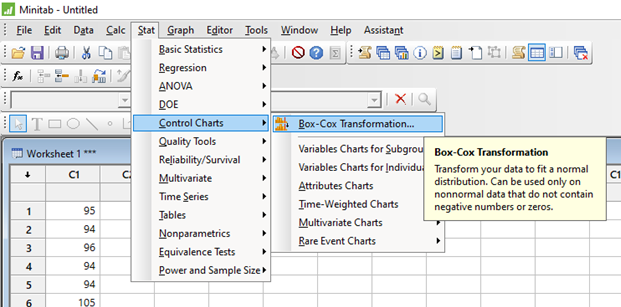
Aceptando en Test de Box Cox.
Se abre el siguiente cuadro de diálogo:
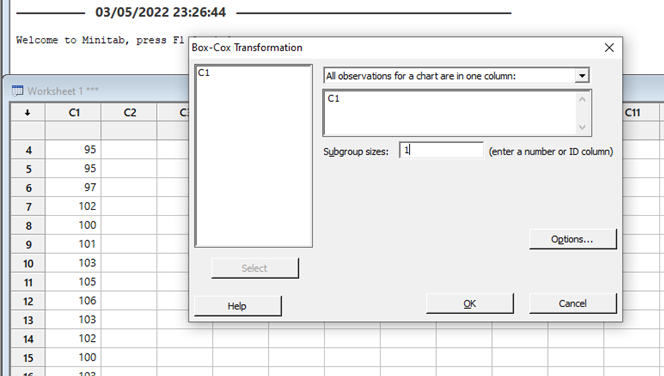
Seleccionamos la columna a analizar
Hacemos click en Opciones (abre el 2do cuadro de diálogo)
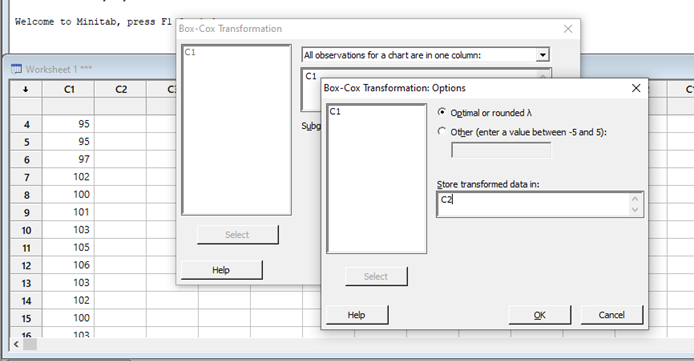
Elegimos la columna donde salvar los nuevos datos
Seleccionamos el Lamda óptimo
Hacemos click el OK en los 2 cuadros de diálogos
Nos aparece la columna 2 (C2) con los datos transformados y el gráfico de la variación de Lamda,
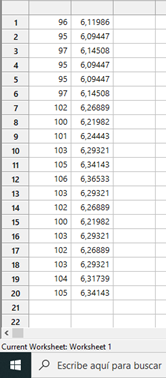
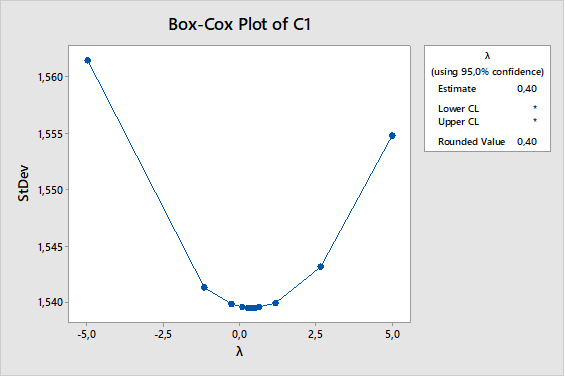
Volvemos a realizar el test de normalidad
Realizamos el ensayo de Normalidad, pero sobre la columna de datos transformados.
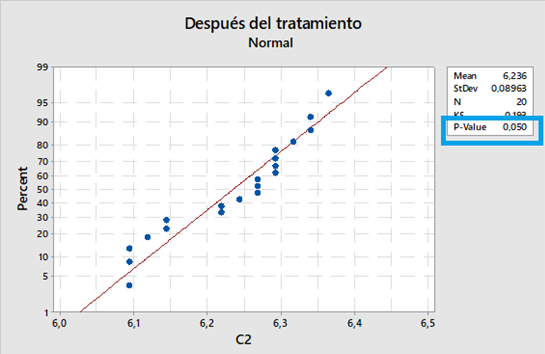
El Valor p es igual que α (0,05), por lo tanto, No rechazamos la H0, asumimos que se Normalizó la distribución.
Ahora si podemos efectuar el cálculo de la capacidad del proceso con los datos normalizados.
Espero que les haya resultado útil.